
Introduction
At Meesho, we offer a wide variety of in-app advertisement programs to our sellers to promote their products within the app and help in accelerating their business. These advertisement programs are a significant revenue contributor for Meesho and fuels our company’s journey.
At the core of all advertisement programs is ad-server, a microservice that powers the Ads that are displayed on the Meesho app. To maintain exceptional user experience and optimize Meesho’s revenue it's very important to display personalized Ads to our users. To achieve this, we analyze vast amounts of clickstream data from millions of users and generate personalized Ad product recommendations for each user basis their browsing history.
These Ad recommendations are re-computed every few hours and pushed to the ad-server, which are then used to power the Ads displayed on the app. This blog delves into how Meesho’s ad-server consumes huge volumes of recommendation data seamlessly
Problem Statement
Meesho’s ad-server has to power millions of Ad requests every minute coming in from the users browsing our app. Parallely, it also needs to consume TB’s of recommendation data coming in every few hours to personalize the Ads for better experience of our users. We needed to find a cost-effective and scalable solution that will let us do this seamlessly.
Some of the key challenges we faced include:
- Seamless Ad serving: Our first and foremost challenge was to ensure that serving of Ads does not get disrupted while the ad-server consumes the new set of recommendations
- Scalability: As a fast growing company, the traffic on ad-server and the data size of recommendations would increase continuously with the increasing users and new personalization features that would come in with time. We needed to find a solution that could scale horizontally to 3x increase in Ad serving traffic and 5x increase in data size
- Cost Efficiency: At Meesho, we aim to be the cheapest shopping destination for our users. To achieve this it’s really important to have a cost effective tech stack. We need to find a solution that would consume minimal resources to keep the cost in control.
Solution
In our exploration for solution, we came across Bulkload technique in Hbase, an efficient way to load large amounts of data. Hbase is a highly scalable, distributed non-relational database. At Meesho, we have been using Hbase in multiple use cases for high throughput random reads accompanied by large data volumes. Using Hbase with the bulkload technique seemed to be a very good fit for our problem.
Following section explains the bulkload technique in more detail.
Conventional Write Mechanism in HBase
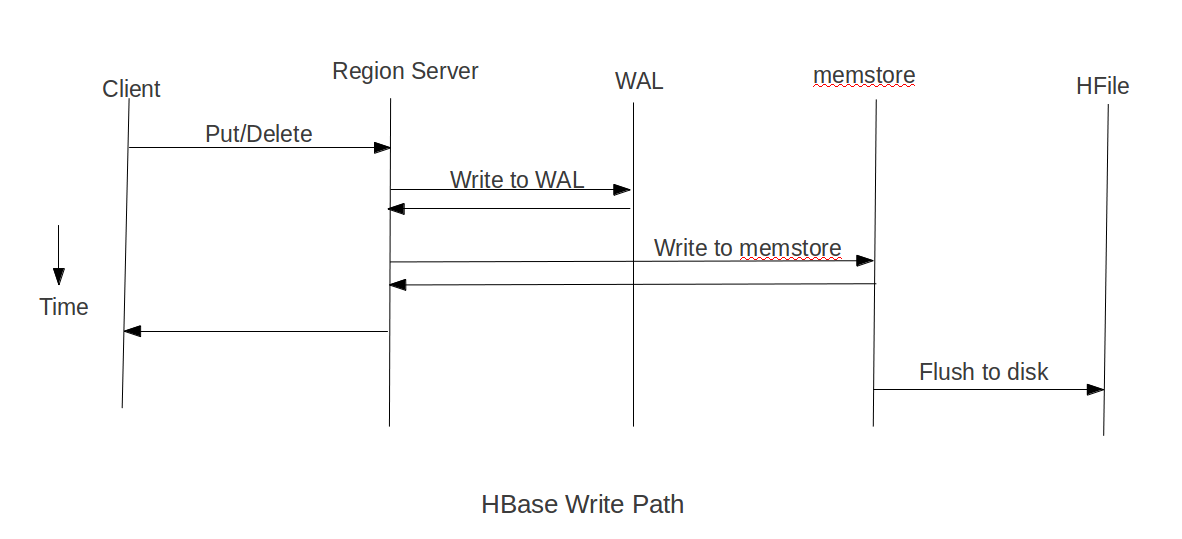
In the conventional write path of Hbase, data is first written to a Write-Ahead Log (WAL) for durability. Simultaneously, it's stored in an in-memory Memstore, which is flushed periodically to create immutable HFiles on disk. In the background, compactions are run regularly which merge multiple HFiles into a single HFile to optimize for read latency.
Bulkload Approach in HBase
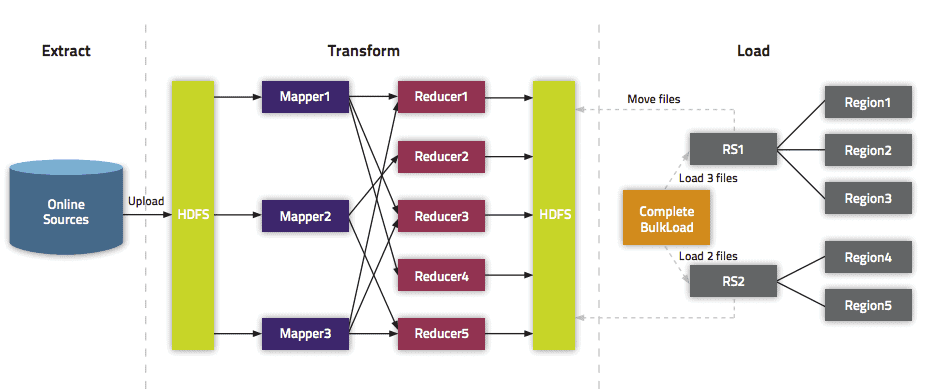

Complete Pipeline
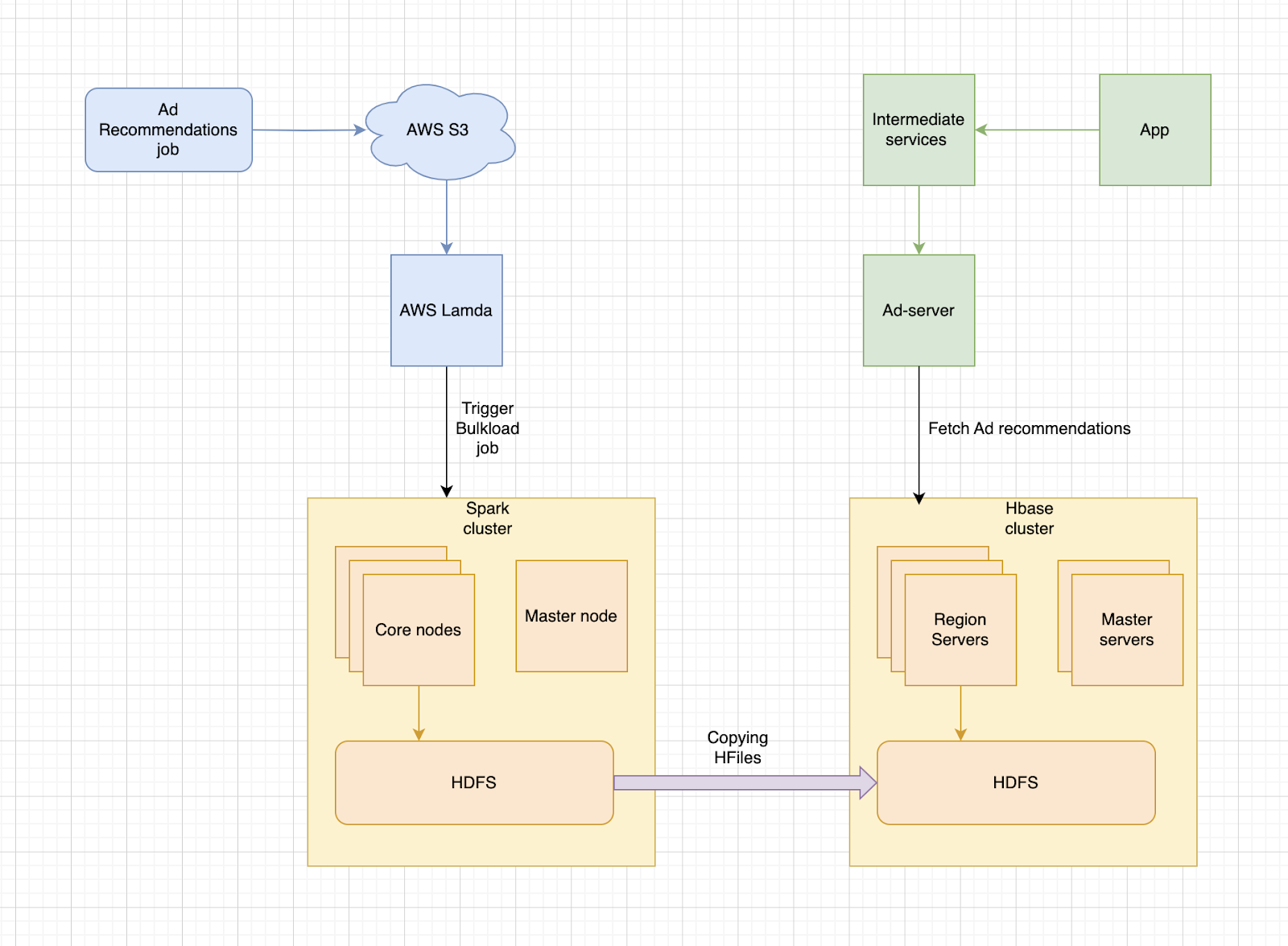
Above diagram describes the end-to-end data flow of the ad-server. The pipeline starts with a Ad recommendations job pushing the recommendations to S3. A Lamda function gets invoked upon the arrival of a data dump, which triggers the Spark job. The Spark job uses MapReduce utility provided by Hbase to generate the HFiles and saves it onto the HDFS of Spark Core nodes. These HFiles are then copied onto the HDFS of Hbase cluster using the bulkload utility provided by Hbase
Performance Analysis
For the remainder of this blog, we will delve into comparing the performance of ingesting a ~300GB data dump into HBase using the conventional write mechanism vs Bulkload.
Infra Setup

Test Scenarios
We created a new Hbase cluster in AWS and imported a test table containing 300GB of data. We simulated read traffic by loading up Hbase with bulk get commands at a consistent throughput of 1000 RPS. Each bulk get command fetches 3 random rows from the test table. We then ingested 336 GB data into Hbase via both the approaches that we discussed above and compared the efficiency and impact on Hbase performance of these approaches.
Below graphs show the read latency and Hbase CPU when then are no writes happening and the Hbase is just loaded with read traffic
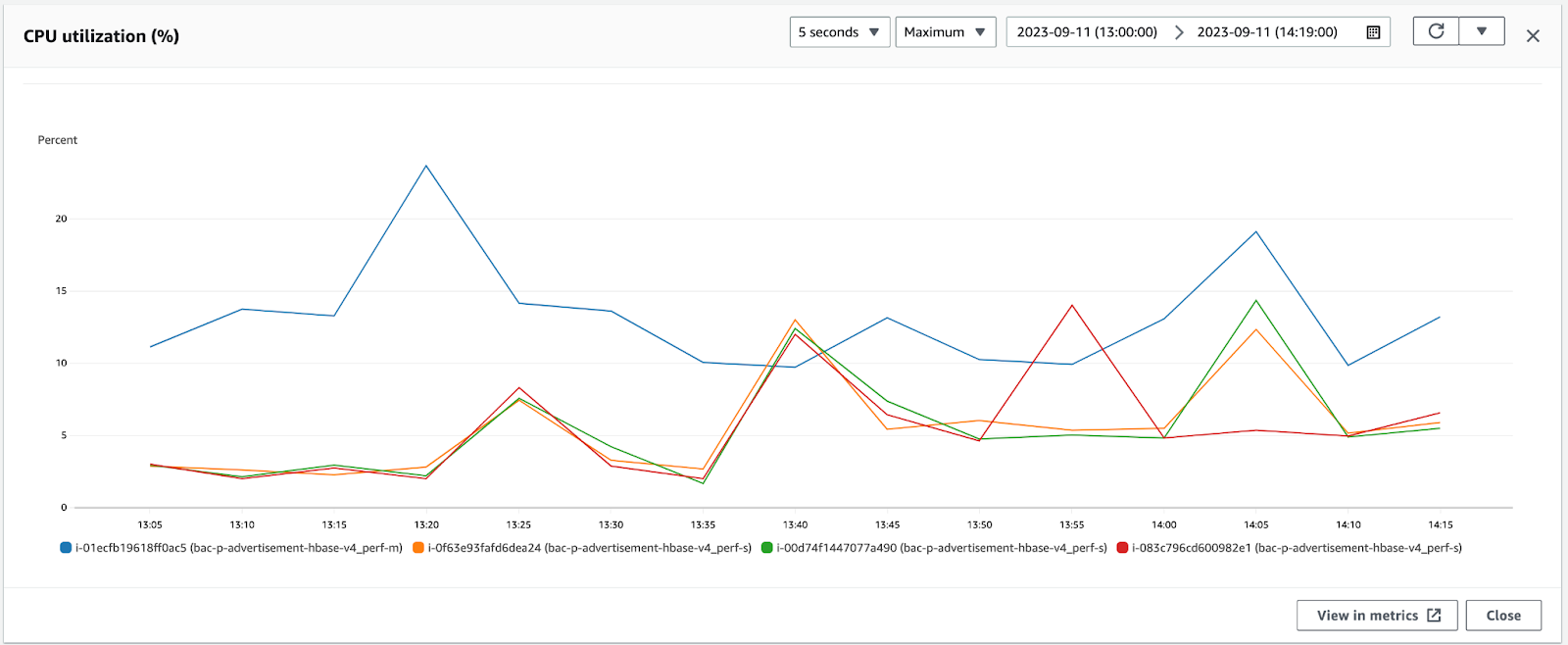
Approach 1 : Bulkload using Spark
While keeping the read traffic consistent at 1000 RPS, we initiated a Spark job which ingests a 336GB dataset into Hbase via Bulkload. The table is pre-created with 100 regions so that there wouldn’t be any region splitting in between the process. Below graphs show the read latency and Hbase CPU during the ingestion.
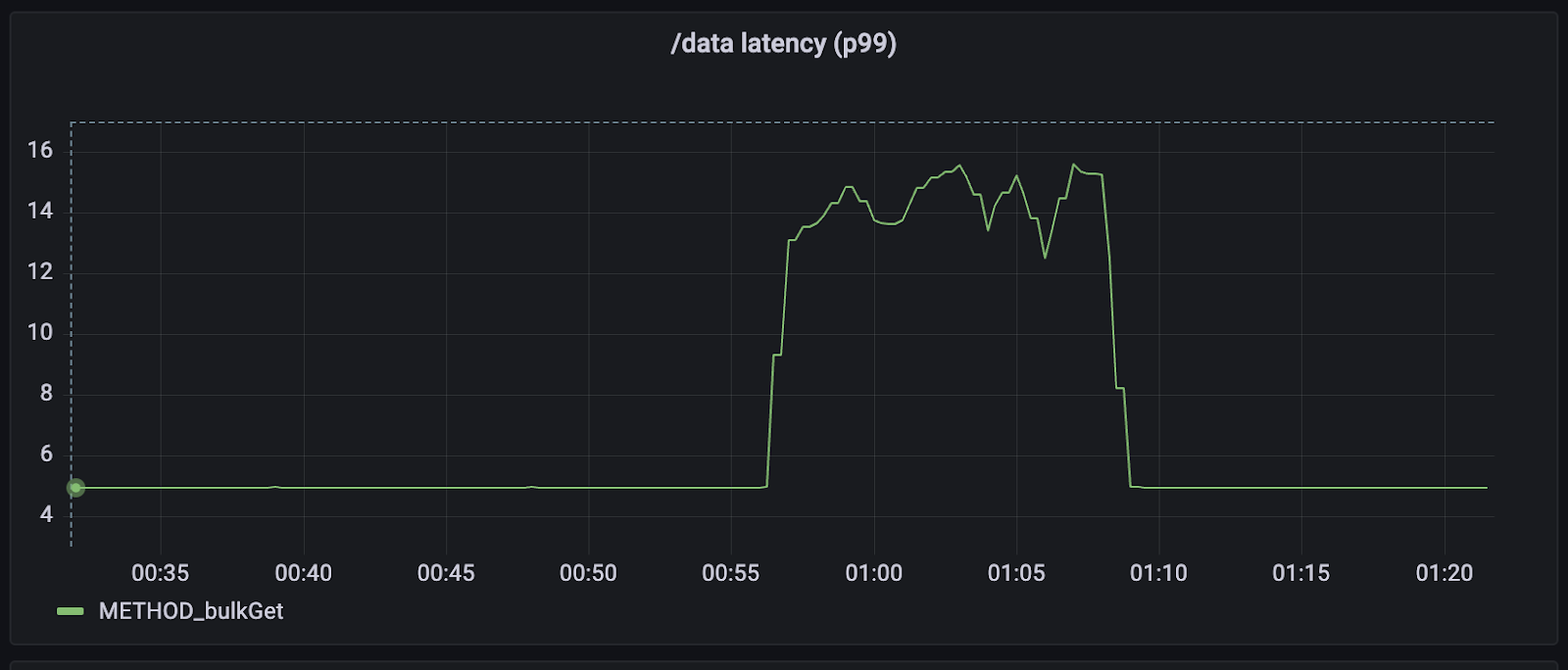
The Spark job's overall execution took 30 minutes: 17 minutes for HFile generation and 13 minutes for copying of HFiles from Spark to Hbase. The read latency of the HBase Bulk Get commands spiked from 5ms to 15ms during the HFile copying phase. During the same time Hbase CPU has also increased to 30%.
Time taken for HFile generation can be further reduced by increasing the number of Spark nodes. HFile copying can be sped up by increasing the number of threads used for copying in bulkload utility. Please note that increasing these threads will result in more impact on Hbase resources which can be mitigated by scaling-up Hbase region servers.
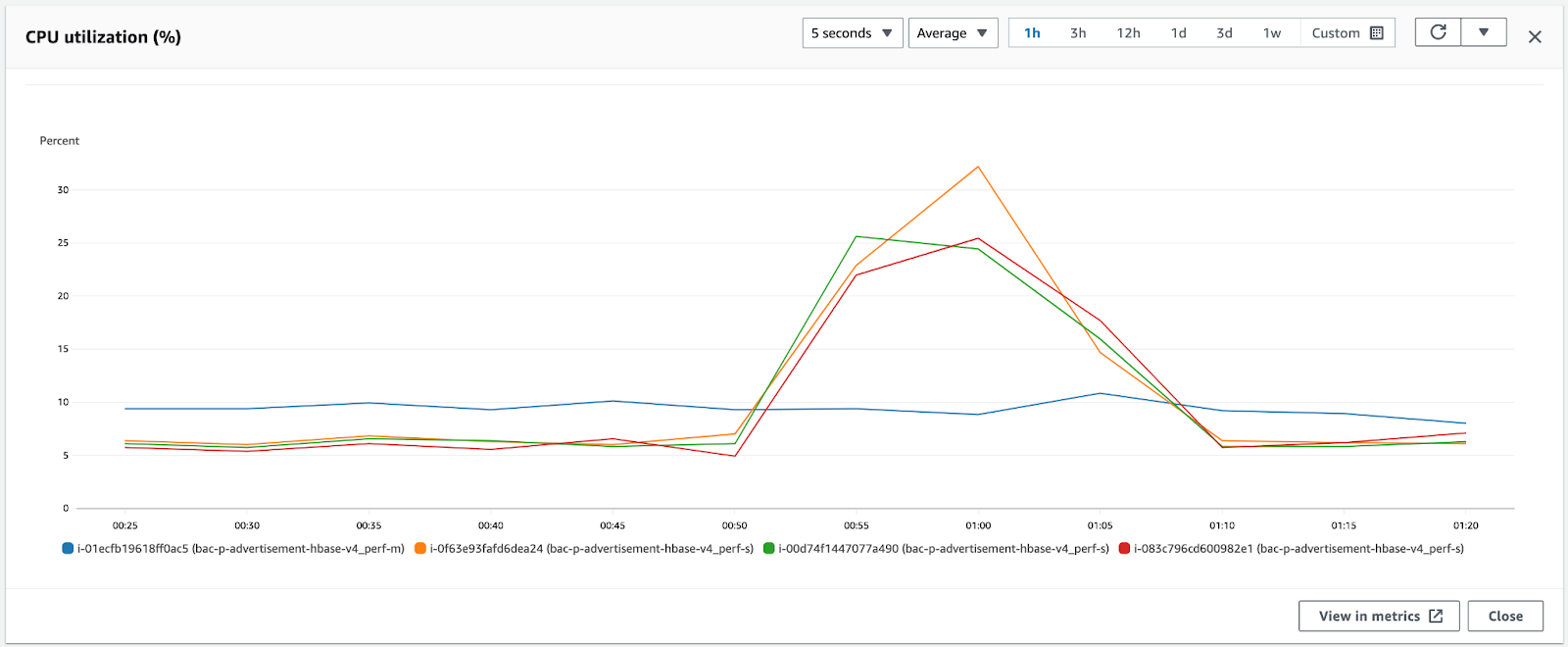
Approach 2 : Ingest with script using conventional Hbase put commands
In this approach, we ingested data using Hbase Bulk Put commands with each command inserting 50 records at a time. To speed up we ran the ingestion parllely from 3 different instances. Overall ingestion took around 3.5 hours. During the ingestion read latency spiked from 5ms to 250ms and HBase CPU reached 54%.
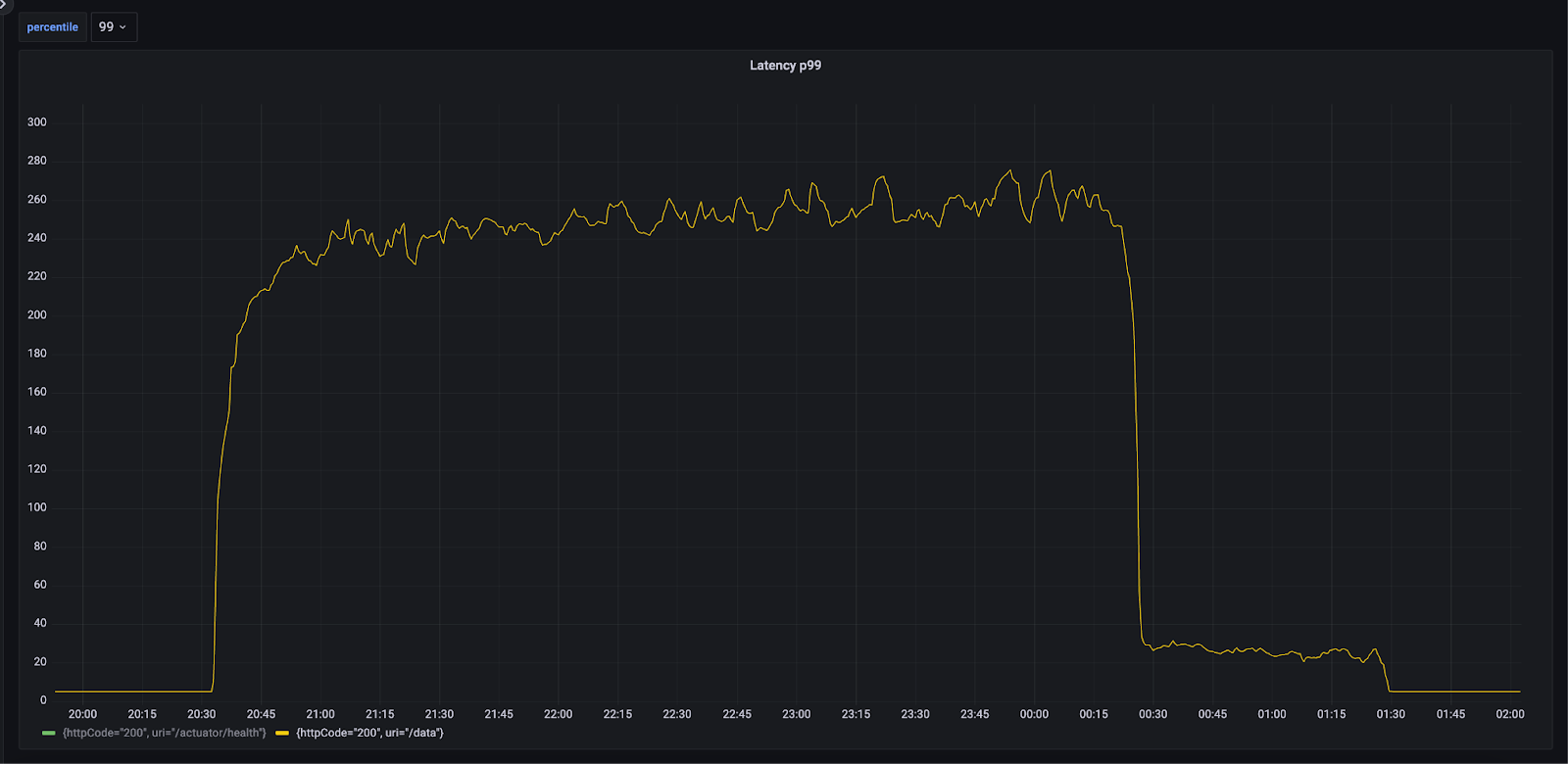
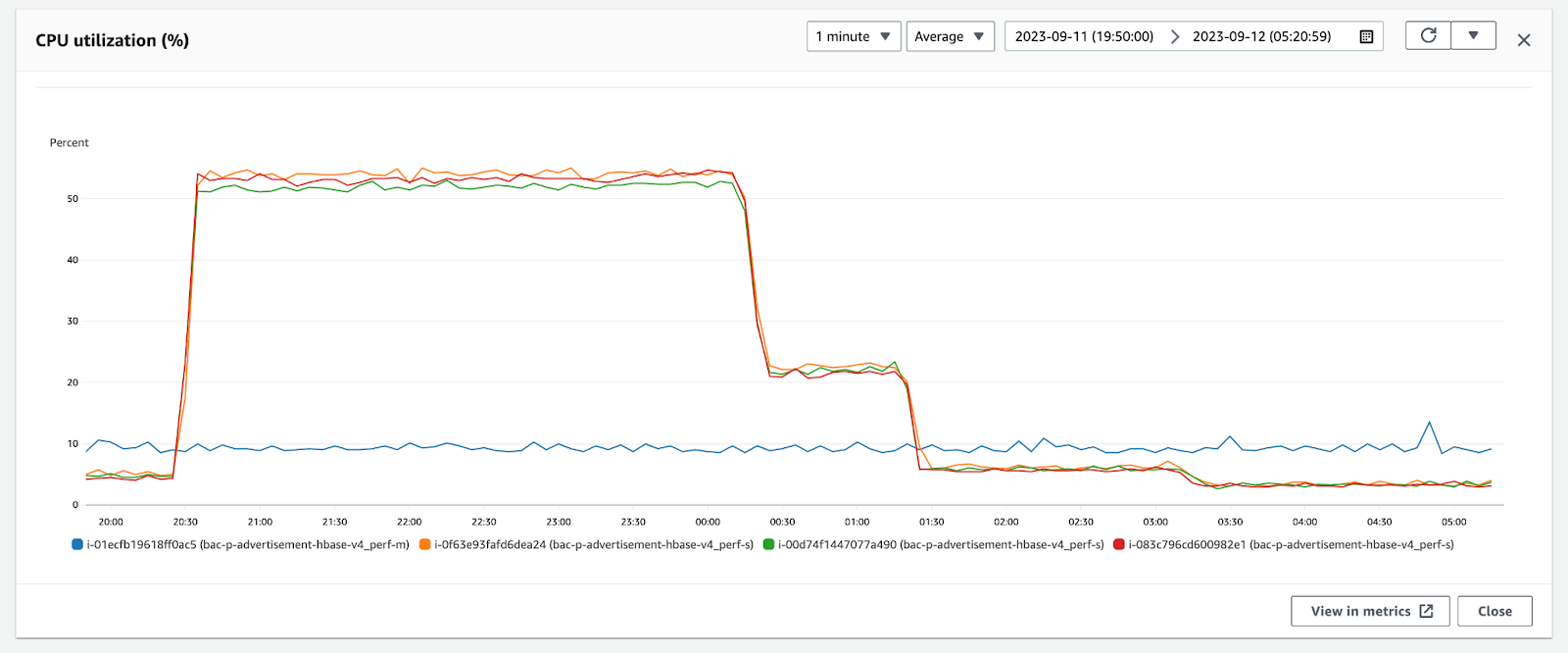
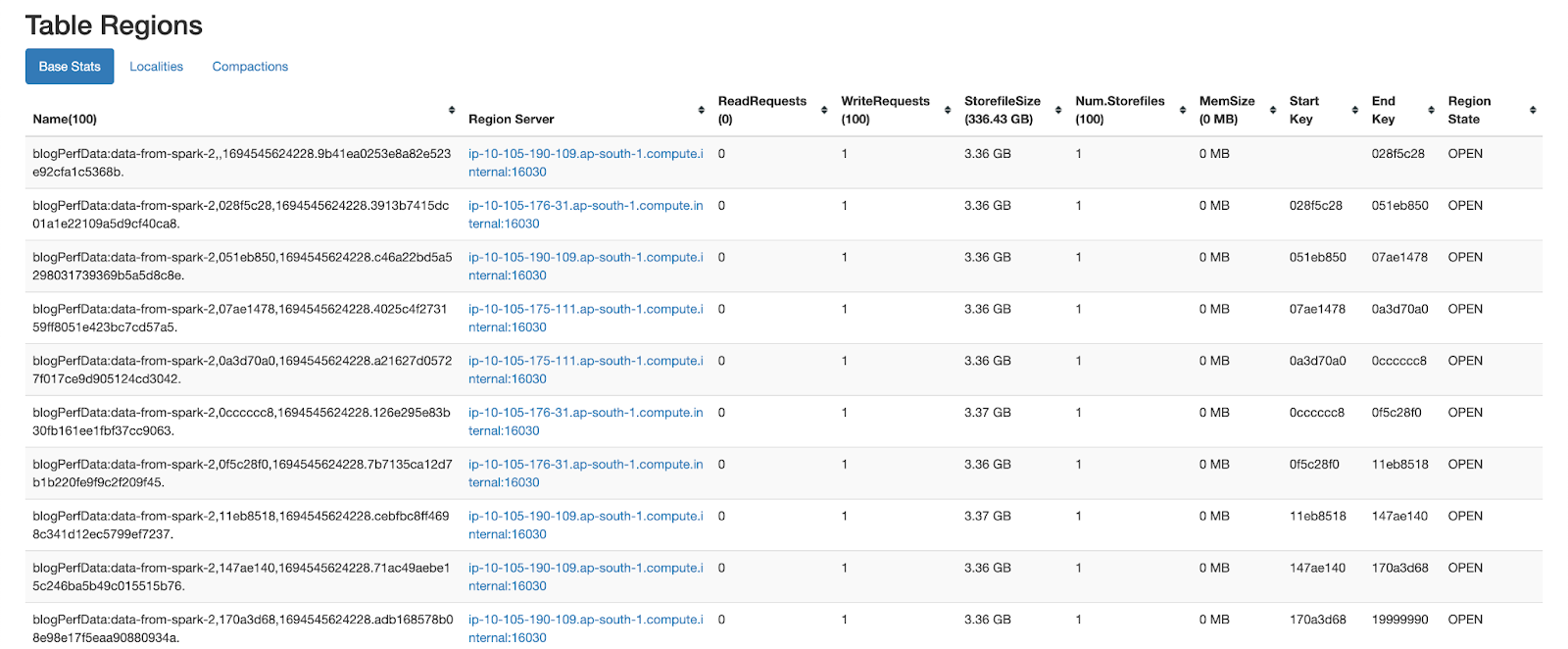
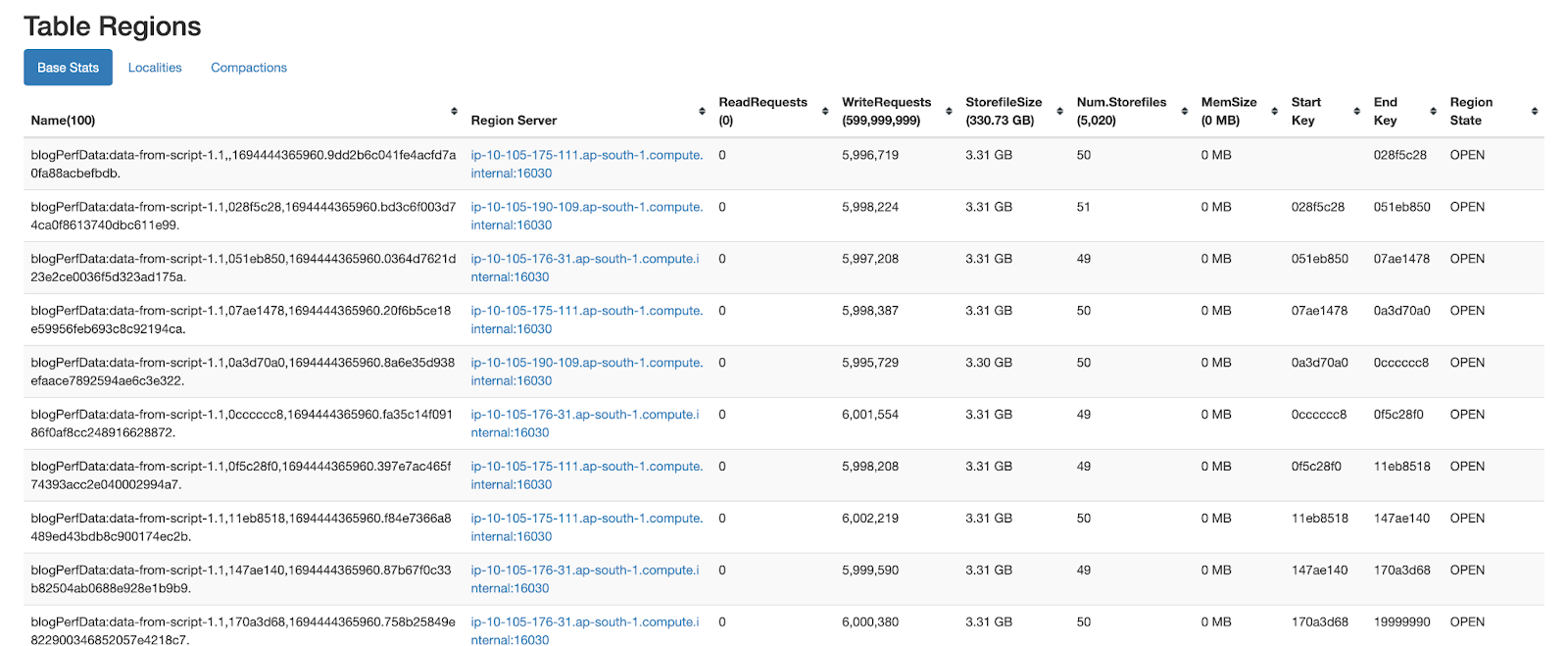
From the below snapshot, we can observe that around 50 storefiles are created in each region. Due to high number of storefiles, reads on this table would incur high latency. Hence a major compaction needs to be triggered on the table to optimize the latency. Due to high resource utilization, major compactions degrade ongoing queries on the Hbase and are usually run in off-peak times. This will be a concern for our ad-server usecase as we would be getting multiple recommendation datasets within a day and we need to consume them even during the traffic times
Performance Comparison

Cost Comparison

Conclusion
From the above analysis we can clearly see that Bulkload is a much faster, lighter and cheaper approach to ingest large datasets into Hbase compared to conventional put commands. Data ingestion time with bulkload has reduced by 85% against the time taken with conventional put commands. The cost of ingestion is also cheaper by 50% and the approach had minimal latency impact on the other ongoing queries in the Hbase.